
Project: Perfect Run
Dissecting the Real AI Crisis - Mitigating Racial Bias in AI
Introduction
On January 9th, 2020, Robert Williams was arrested for stealing thousands of dollars worth of watches from luxury store Shinola. After the exploited store owner provided the Detroit police with grainy surveillance footage at the time of the robbery, it was sent up to the Michigan police department for review through their facial recognition system. The facial recognition technology (FRT) revealed Williams to the perpetrator, and he was told to surrender himself and spent the next 18 hours facing harsh detainment, and the 12 after that imprisoned. What would be a commendable effort on behalf of FRT and artificial intelligence (AI) in a forensics setting quickly becomes a cautionary tale, as Robert Williams in fact did not commit the crime he was incarcerated for. He was misidentified by the police station’s FRT for another black man.
Unfortunately, after the shocking account of Robert Williams speaks volumes on the state of a real-life AI crisis. One where the majority of the public faces misidentification in FRT and other AI systems. According to the Washington Post, Asian and African-American people were up to 100 times more likely to be misidentified than white men, depending on algorithm and search (Washington Post, 2019). Refer to the photo above for another example of misidentification in AI systems– the White Obama case study, where an AI upscaling pixelated images failed to account for people of color, even registering a turban as hair. As a minority myself, my facial features are far from conventional. My unique features that I cannot alter in any way would certainly cause misidentification in some of these systems. Therein lies the problem– people being inadvertently marginalized due to a lack of care nor representation in the labs making these systems. While I haven’t had any first-hand experiences regarding misidentification, this prevalent issue could affect any minority demographic. The crux of the matter with certain AI systems like facial recognition, natural language processing (NLP) and consumer-AI devices is that they often don’t work as intended for people of certain racial or ethnic backgrounds. This shows the inherent bias that many AI systems have, directly caused by a shortage of diversity in the labs that formulate these algorithms and collect data. These deployed systems are often not trained on data that includes a variety of diverse individuals. While machine learning (ML) is self-taught, withholding integral data representative of a demographic prevents the AI/ML systems from working effectively for all users.
To combat these distressing statistics, I have composed a small-scale project that will run for a year to help combat racial bias in AI systems and adequately implement comprehensive data representative of all underrepresented demographics– Project: Perfect Run. Serving as the “perfect run” at diversifying the data process of extract, transform and load (ETL), this project is a small-scale one year project that will occur in partnership with the Artificial Intelligence Institute at the University of South Carolina (AIISC). Research participants will actively aid in a model research study that revolutionizes how data fed to AI/ML systems is collected, whose framework is meant to be adopted by AI/ML firms. Ideally, Perfect Run will serve as the catalyst starting the conversation on AI ethics, and ensure that everyone is accounted for accurately in FRT, so that we never have another cautionary tale like Robert William’s again.
Key Insights and Impact
All three of my key insights have given me the necessary skill set to launch and oversee Project Perfect Run.
| Key Insight | Application |
| Cybersecurity Iceberg - Expanded upon my knowledge of risk management of information systems and networks from in the classroom to bridging it to my everyday life, where we encounter and manage risk on the daily. | My background in cybersecurity and knowledge of the cybersecurity iceberg has definitely revolutionized the way I view data collection and integrity. My understanding of risk management will be critical in the ETL process, as there are a multitude of privacy concerns that can arise from collecting participant data and biometrics, even if it is for the sake of research. To maintain equity and integrity, Perfect Run will foster close collaboration with the Governance, Risk and Compliance (GRC) team to ensure data privacy and AI ethics are carefully reviewed. |
| On Privilege & Intersectionality - That intersectionality is an important tool to understand how multiple layers of identity can result in more angles of discrimination in society. Understanding and respecting other people’s positionality is something we should strive for. | My approach to navigating intersectionality within Perfect Run will make or break the project. The purpose of the project is to gather data for underrepresented demographics, so assessing marginalized social identity layers will be critical for the segmentation, targeting and positioning (STP) plan. Unlike the superficial analysis other AI/ML firms have of a demographic, resulting in little to no representation in FRT, my understanding of privilege will assist in crafting an equitable and diverse work environment. |
| Speaking With Conviction - That intersectionality is an important tool to understand how multiple layers of identity can result in more angles of discrimination in society. Understanding and respecting other people’s positionality is something we should strive for. | Learning to overcome my speech anxiety and speaking with conviction is of the highest importance. Without strong interpersonal and communication skills from the project manager, the project is doomed to fail. Excellence in oral and written communication skills will facilitate the recruitment, hiring, negotiation and management requisites needed to start research. |
Proposed Approaches
In addressing the issue of racial bias in AI/ML, the solution lies in collecting diverse data and ensuring data collection technologies are impartial yet inclusive for all users despite demographic. All AI systems are contingent on data analytics, the process of inspecting, cleaning and transforming data with the goal of supporting decision-making. Regarding FRT, remediating bias in these systems is fairly straightforward. The key to diverse data extraction is the ETL process, where extracted FRT data must be accumulated from a variety of sources, including live research participants and photos on the internet.
As previously mentioned, Perfect Run is a small-scale AI/ML project with the goal of mitigating bias in FRT. Meant to be replicated on a larger scale at a further date, Perfect Run will partner with the USC’s own Artificial Intelligence Institute at the University of South Carolina. Perfect Run will be quite costly, totaling to $1,500,000 in awarded grants necessary to fund the project. However, I fully intend for the project to be bootstrapped, and rely on awarded grant and research money. For more information regarding cost analysis and persons of contact, see the "Cost Analysis" section below. Starting in January 2024, the following steps will be taken, starting with the formation of a diverse team. Recruitment will take place within the University, employing current undergraduate and graduate students to collect data and run operations. By January 2025, Perfect Run will conclude where an evaluative and postmortem analysis will be conducted to evaluate the effectiveness of the project. After evaluative metrics have been taken into consideration, primary data collected will be packaged, labeled and securely stored. To conclude perfect run, our internal data ETL process will be revised and optimized for modeling to suggest to other AI firms in the FRT stratum.
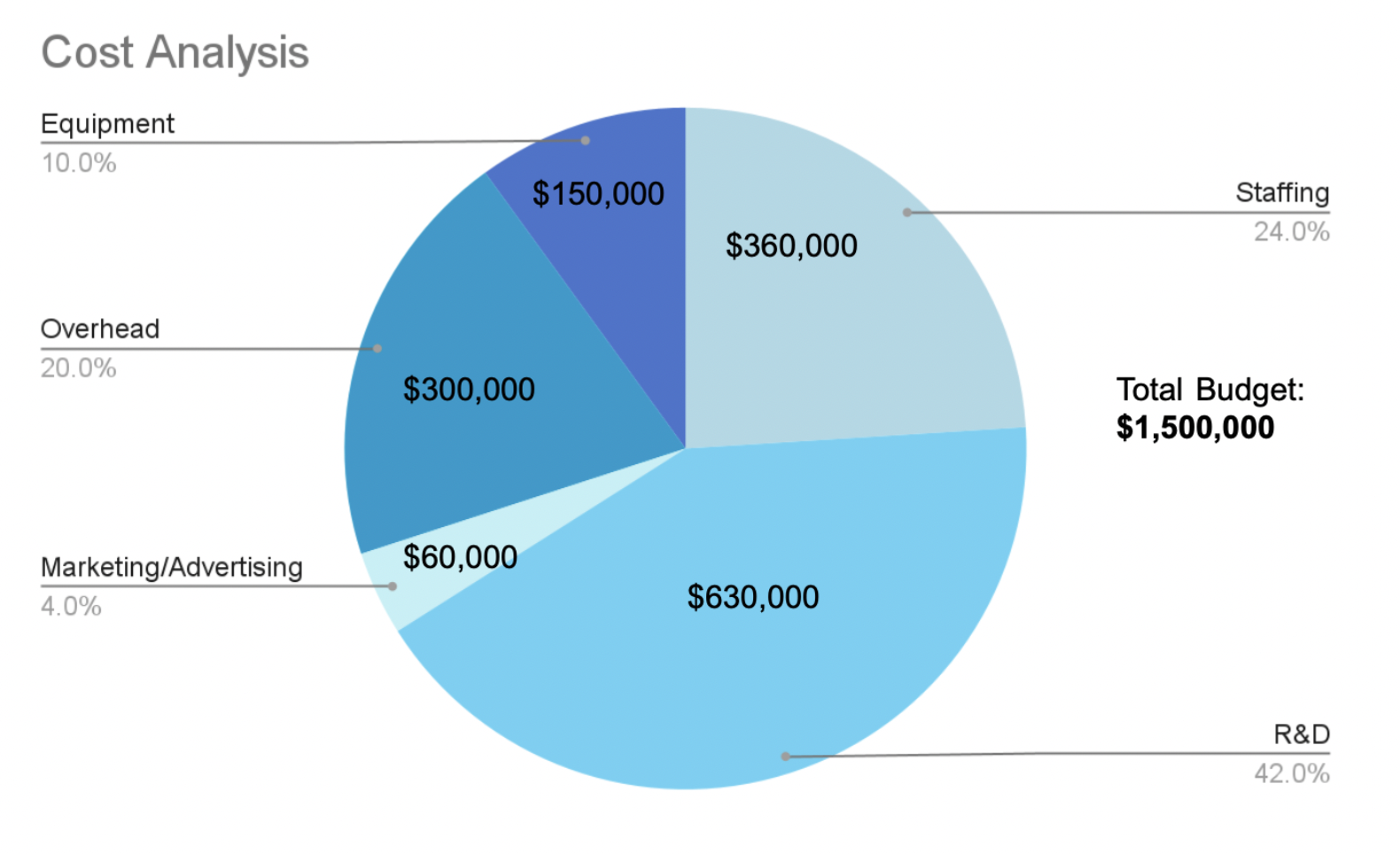
1. Forming a Diverse Team
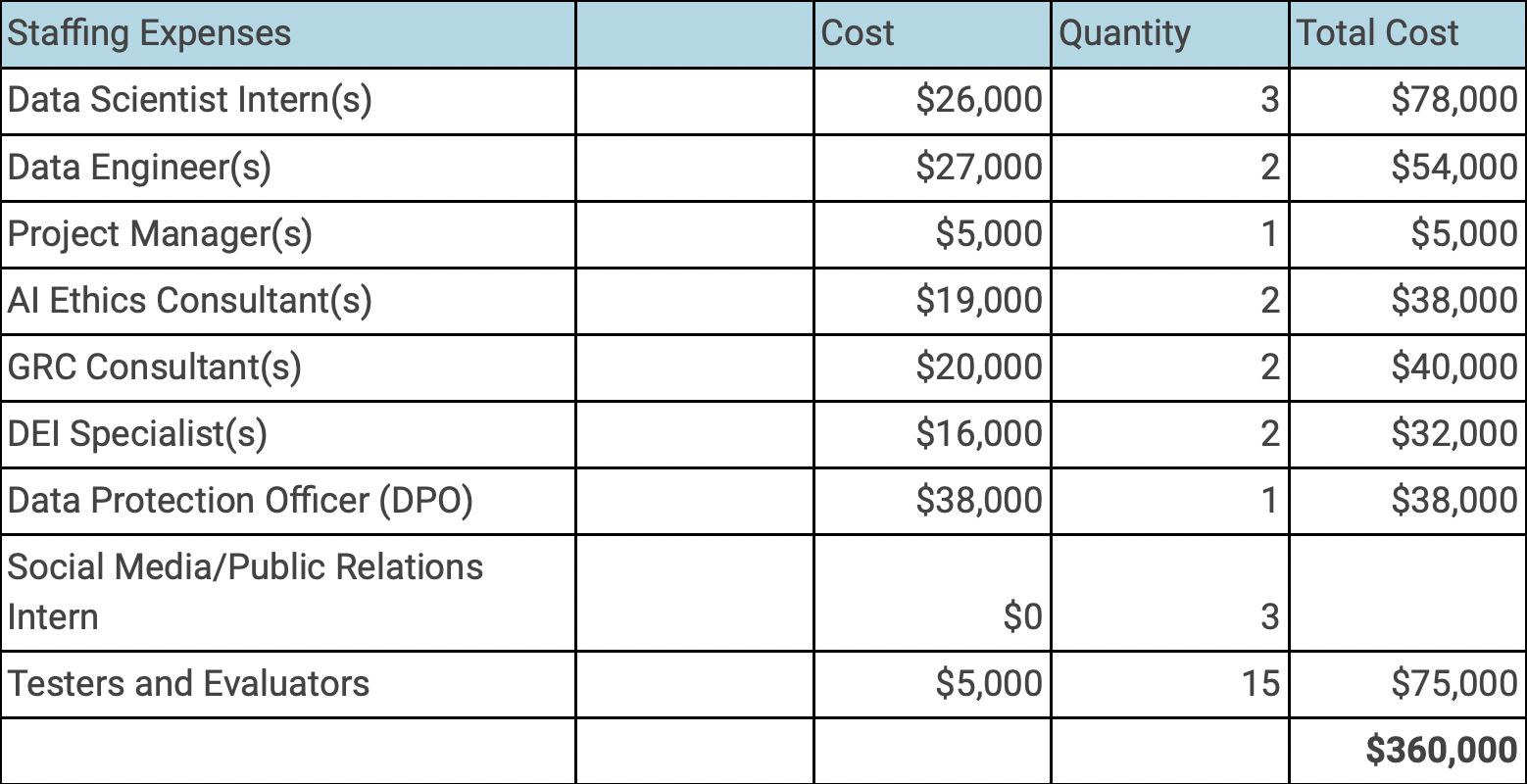
Perfect Run will establish diversity and inclusivity as top priorities for everyone involved in the project. No matter a data scientist, a participant, a contractor nor a front-end designer, an unbiased and equitable hiring process will be employed, based on qualifications and skills, while accounting for historically underrepresented demographics of FRT. Research contributors will principally consist of current undergraduate and graduate students matriculating at USC’s College of Engineering and Computing (CEC), or other relevant colleges related to the project. USC alumni in relevant majors will also be considered. While students will get real-world experience serving in roles as scientists, engineers or consultants, they will receive a low salary comparable to an “intern” of their respective roles. With a working budget of $360,000 to employ the necessary 31 students for the year, research contributors can expect a low salary recompensed by significant equity and research credit for contributions to Perfect Run. Potential academic credit for related courses will also be offered as an incentive, especially for courses like CSCE 587 and CSCE 585. Employment opportunities will also be disseminated through Handshake and STEM organizations at the CEC, including volunteer positions to allow additional students to gain work experience. Carefully throughout the entirety of Perfect Run, frequency distribution of all races/represented demographics should be equal. Team members should be passionate about AI, taking a step towards racial equality in AI/ML systems and should possess relevant skills to streamline the deep learning process. Implementation of diversity in upper management will be crucial, ensuring all targeted demographics have a hand in the project and be fully represented.
Forming a diverse team of researchers and engineers already counters the majority of those formulating AI. For Perfect Run, compensated essential staffing will consist of two data scientists, two data engineers, the project manager (me, who will accept little to no salary as I am vested in the project), two AI ethics and GRC consultants, two DEI specialists, three social media interns and fifteen testers. Each role can be fulfilled by a student, with the exception of the Data Privacy Officer (DPO). Since this is in fact a real research project, Perfect Run must comply with local data privacy laws, so a highly qualified and preferable SME will serve as our DPO to prevent litigation down the road. Throughout the hiring process, considerations regarding racial sensitivity and representation of marginalized demographics will be made within our best judgment.
2. Marketing and Advertising
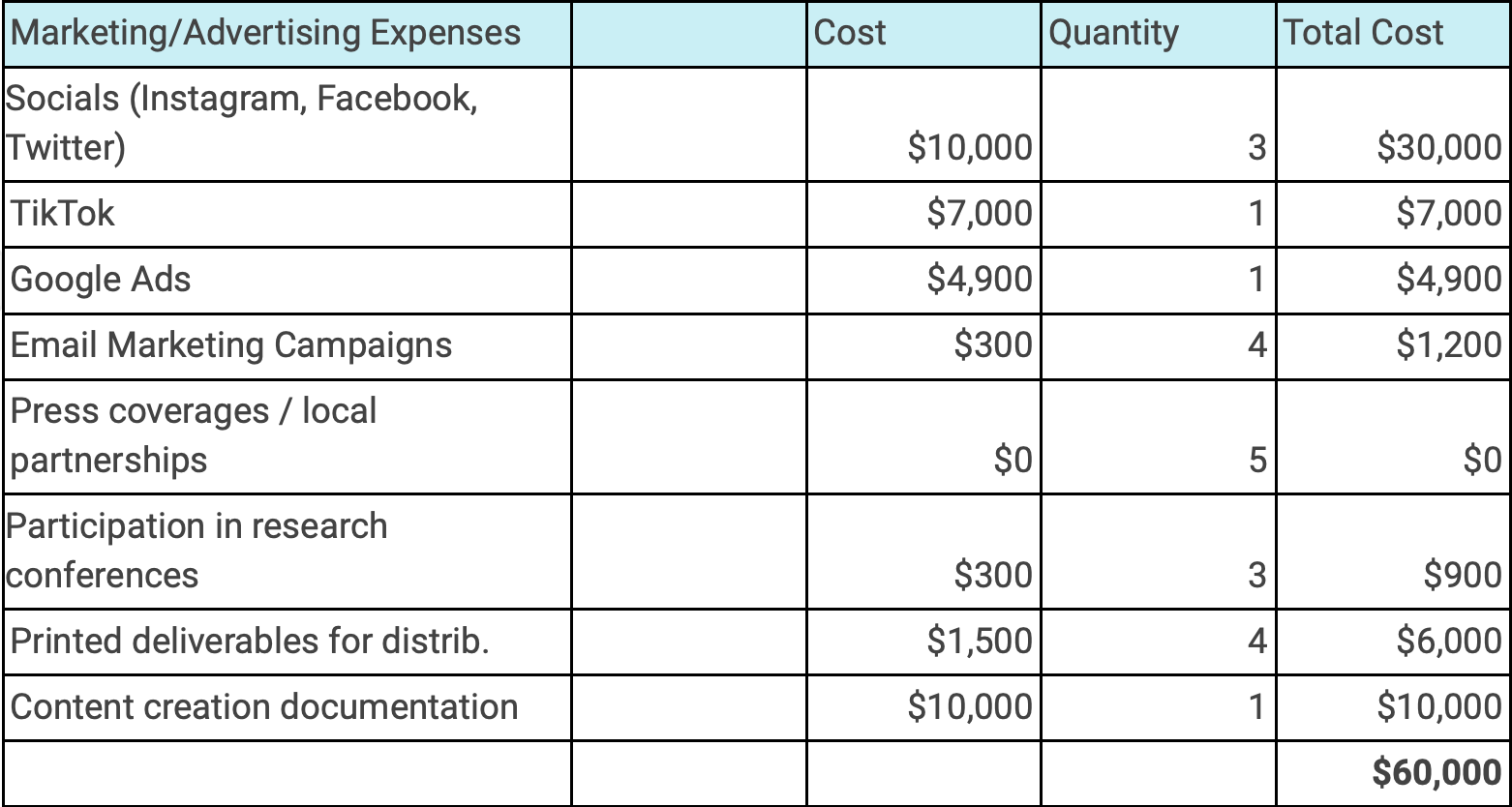
Before the data extraction process can begin, we must first connect contributors with our target audience– willing research participants susceptible to the hazards of misrepresentative FRT. Putting the $60,000 allocated for advertising to use, the marketing phase of Perfect Run will consist of making the University of South Carolina aware of its existence. Clearly defining our goals, the scope of the project and the intended outcome, advertising will come in both physical and digital mediums. Digital mediums include social media advertising (Facebook, Instagram, Twitter), Google Ads, a project overview in the Daily Gamecock, a GroupMe chat for questions and an application hub on the official University website. Digital advertising will be under the social media interns’ purview. Physical mediums will include descriptive posters in the Swearingen, Darla Moore, iSchool, Coker and Williams-Brice buildings. Personal outreach from research contributors is another physical medium, team members attending meetings of various STEM, multicultural and LGBTQ+ extracurricular organizations to register interest and meet diverse individuals face to face. Research participants will preferably be current USC students from multiple demographics, though alumni and Columbia denizens.
The bulk of the marketing budget going to advertising mediums leaves around $20,000 surplus for miscellaneous marketing expenses. With this, remaining funds will be invested into content creation to document the research process throughout the year, launch email campaigns to further penetrate the target market and create deliverables for auditing purposes. An intrinsic reward that comes with using the surplus to further develop the public aspect of the project will be deliverables in the form of analytical reports and statistical IP that will greatly enrich each research contributor's student portfolio. The work created and documented in Perfect Run will prove that team members were highly qualified and possessed a discipline to excellence with work that speaks for itself.
3. Data ETL
The core of Perfect Run will come from its innovative data ETL process. With a skilled and qualified team of student developers and data scientists to assist with data collection, contributors can apply to their corresponding role what they’ve learned in class.
Loading our internal AI system will be rather straightforward, but will require a copious amount of primary and secondary data. In extraction, FRT data will come from both, secondary data collection of underrepresented demographics from the internet, and primary data that our firm will conduct requiring active research participants. Note that throughout the data extraction process, the legality of data collection and data privacy laws will be explicitly stated to participants and contributors alike, so we establish integrity and display corporate social responsibility.
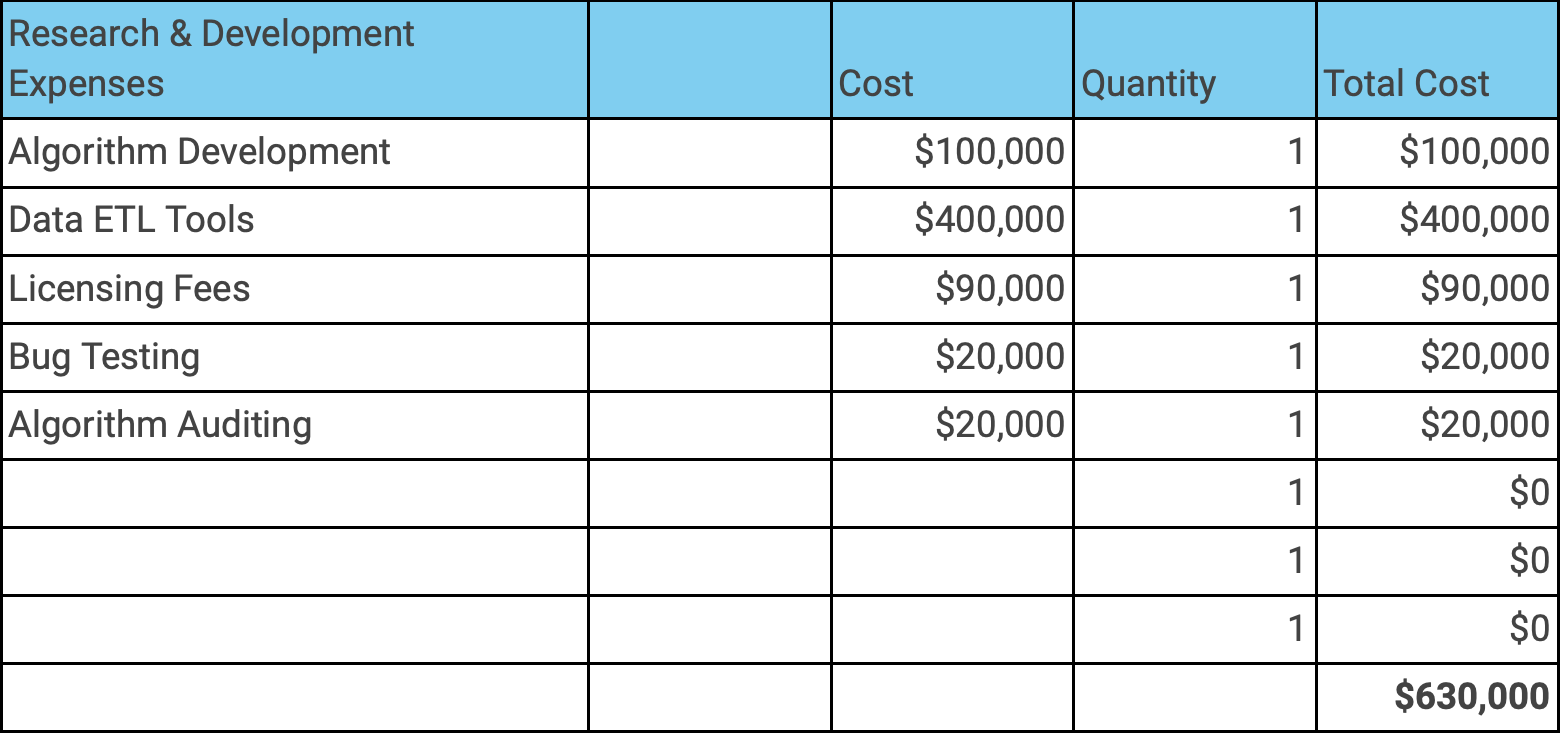
Seeing as this is a smaller scale project, 10,000 images of diverse individuals will suffice for data extraction. Data transformation will entail augmentation of the samples collected by our data scientists, which will optimize the image by adding or reducing noise and other features to best train the AI system. Training the model on what to look for and applying it to each image will allow for great strides in the deep learning part of our internal FRT. Lastly, loading the data will consist of secure storage and segmentation of the data. The PM, DPO and GRC consultants will collaborate to determine the best approach for ethical and secure data storage, and how long the data will be retained before destruction. Decision-making on what the data will be used for, and organizing it by demographic is extremely important to the success of Perfect Run. As an aspiring database administrator after graduation, security of the samples collected in a protected database will reduce the risk of a breach in data privacy of the sensitive biometric data. Overall, the goal of the data ETL process Perfect Run has curated is for the creation of a novelty data backlog that can neatly be preserved. Using the analytics collected, the ETL process will be monetized as a set for a B2B venture to eventually make frequency distribution among other AI systems ubiquitous. Mostly targeted towards FRT AI firms, the ETL process will ideally be applicable to any AI/ML stratum firm for effective and accurate frequency distribution.
By meticulously annotating and registering this sensitive biometric data, we can ensure AI is representative of everyone and preempt disasters that could occur from lack of representation in the lab as the AI takeover becomes more seamless.
4. Measure Internal System Bias
Before getting too deep into the project timeline, Perfect Run and the AIISC’s internal AI/ML systems must be measured. Heavily relying on the testimony of the AI ethic consultants, an internal audit will be held to diagnose and remediate pertinent systems that will be used in the FRT. It will be necessary to preprocess data and filter personally identifiable information (PII). Data engineers and evaluators will examine model architecture, algorithms and training processes. The team will confirm that we hold ourselves to the clear objectives and bias metrics we established at the beginning of the project. This will ensure that equal opportunity and equity are at the forefront of every development and marketing decision made regarding Perfect Run. The process of debugging and algorithm auditing is factored into the project’s R&D costs, totaling to about $40,000 over twelve months.
Conducting an AI research project on racial bias and misidentification without checking our own internal bias would be antithetical. Of our unique approach to have a diverse team and diverse participant pool, the data from each targeted demographic will need to be large, but cohesive. The end result is to have all skin tones easily be recognizable by an AI system, reduce ambiguity for gender fluid or non-binary individuals, and other demographics that may find themselves underrepresented in FRT.
4.5. Improve Internal Algorithms
After sufficient remarks to conclude that our FRT has system integrity and a strong confidence interval, we can move onto improving the existing algorithm. With established stability, now it is time to work towards increasing efficiency and efficacy. Improving algorithms will consist of code optimization and utilizing the full capabilities of the systems hardware for faster results. Improvement in areas like data pipelining and investing research money in cutting age AI techniques or micro-projects will streamline the entire ETL process. Data scientists and engineers will assess model fairness for algorithms and research by using real-world scenarios to measure performance. The PM will implement an interactive development process where cyclic refinement and review of algorithms takes place routinely, even after this audit.
From a security standpoint, internally auditing assets and systems will assist in maintaining probity for Perfect Run. Data integrity and accuracy are the crux of the project, and responsibly collecting and packaging data reflective of each demographic climate is imperative. By the time the project has concluded, a successful internal bias assessment has been passed, and months of routine algorithmic refinement will have taken place. These measures, though seemingly exhaustive, will be critical when it comes to dissemination of our ETL process to other AI systems in the FRT realm. The first initial refinement phase marks the end of the novelty in the project, as data ETL, internal bias review and algorithm refinement will be repeated throughout the project’s entirety, until it concludes in January 2025. Even when algorithms are deemed as “good as they can get,” our raised R&D dollars will still be reinvested into the study.
5. Testing + Evaluation
While this phase refers to the final testing and evaluation of the overall project, it is important to note that the project management model selected will incorporate evaluation metrics at every step of the way. From recruitment to preprocessing to training to data extraction, Perfect Run will have a compensatory scoring system that assesses the authenticity of both the firm and the AI systems used. With how delicate the desired end-result data payload will be, multiple checks and balances will be integrated into Perfect Run to ensure that our data ETL process is ethical, efficient, inclusive and that contributors gain firsthand technical knowledge in AI/ML.
The final testing phase of Perfect Run is easily the most important. Closing routine auditing and refinement will occur one last time before final evaluation, where the FRT system developed will be tentatively decommissioned until data is neatly packaged and ready for data visualization. Evaluation will be another compensatory score system, heavily relying on the consultants to assess strengths and weaknesses of our firm. Quantitative research will be beneficial here, where scientists will work with the PM to create and disperse project postmortem surveys for feedback from research contributors and participants. This gathered response data will (ironically) undergo data visualization, and play a key role in identifying the public perception of the project. After all, the ideas and feedback of those participating in the project is very much germane to our ETL process. Final auditing, postmortem analysis and participant surveys aside, the PM will take the data visualization charts and work closely with the University’s marketing research department to create a marketing mix for how best to propagate the gathered data.
In the name of bootstrapping, after Perfect Run has been completed, research contributors are relinquished of their duties, free to stop working on the project or utilize the Artificial Intelligence Institute at the University of South Carolina dry labs for personal portfolio projects. It is imperative that research contributors understand that after Perfect Run data collection has ceased, no one is allowed to work on it nor access any biometric data extracted, as such would violate data privacy laws. Until the visualized data has been incorporated into a sustainable marketing plan to package our data ETL process, contributors are free to use Perfect Run labs and indirect project resources to their liking.
Since the reiteration of evaluative metrics and confirming data veracity have occurred throughout the entirety of the project, after collection of metadata and feedback, Perfect Run will be complete. Referring to collected quantitative data, I can measure how far off contributors were from our target marks, and gauge the general perception of the project. No matter what impediments contributors face along the way, the end result of Perfect Run is still a payload of diverse data and a unique extraction process that will be replicated on a larger scale. The first of its kind, Perfect Run will be the first attempt at using my skill sets and technical expertise to bring us closer to a world where AI operates under equality instead of equity.
Cost Analysis
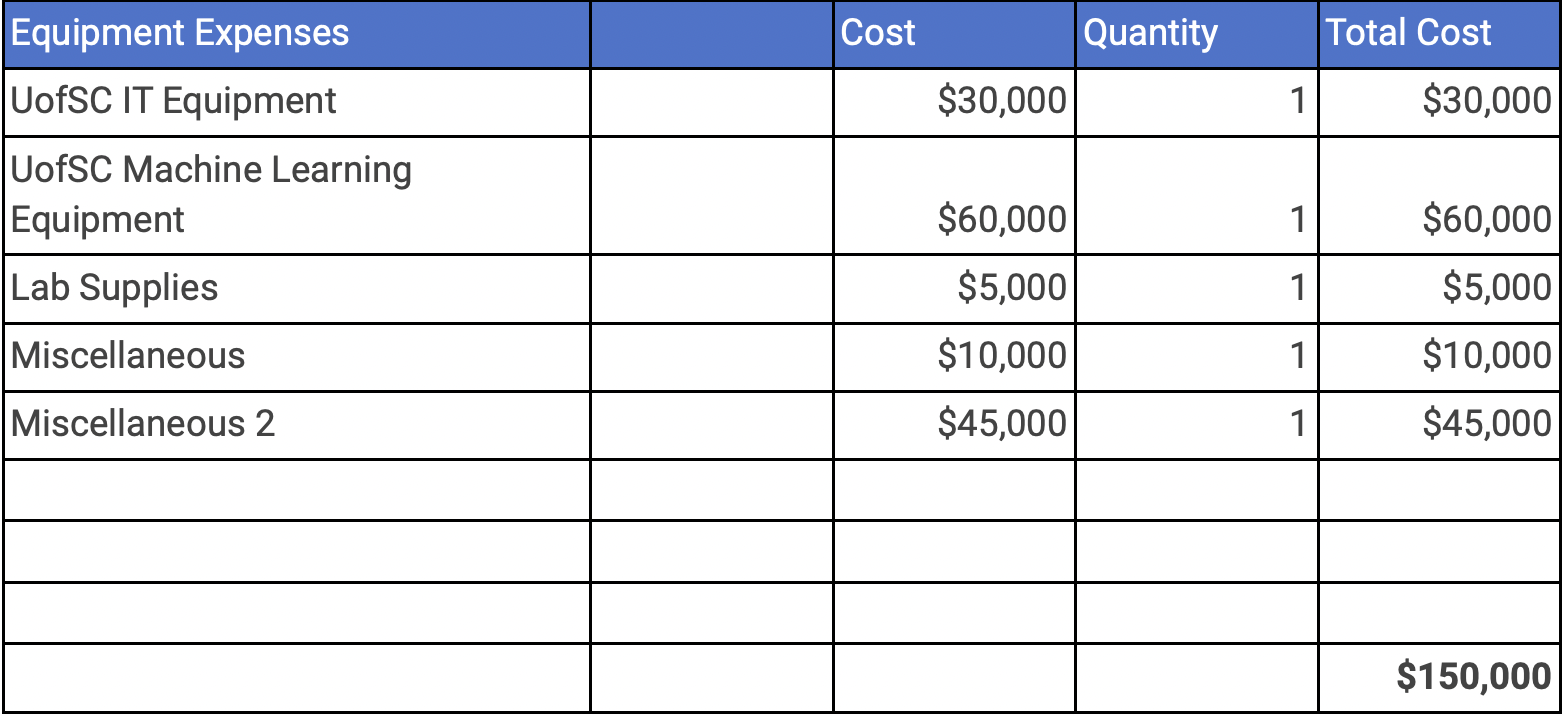
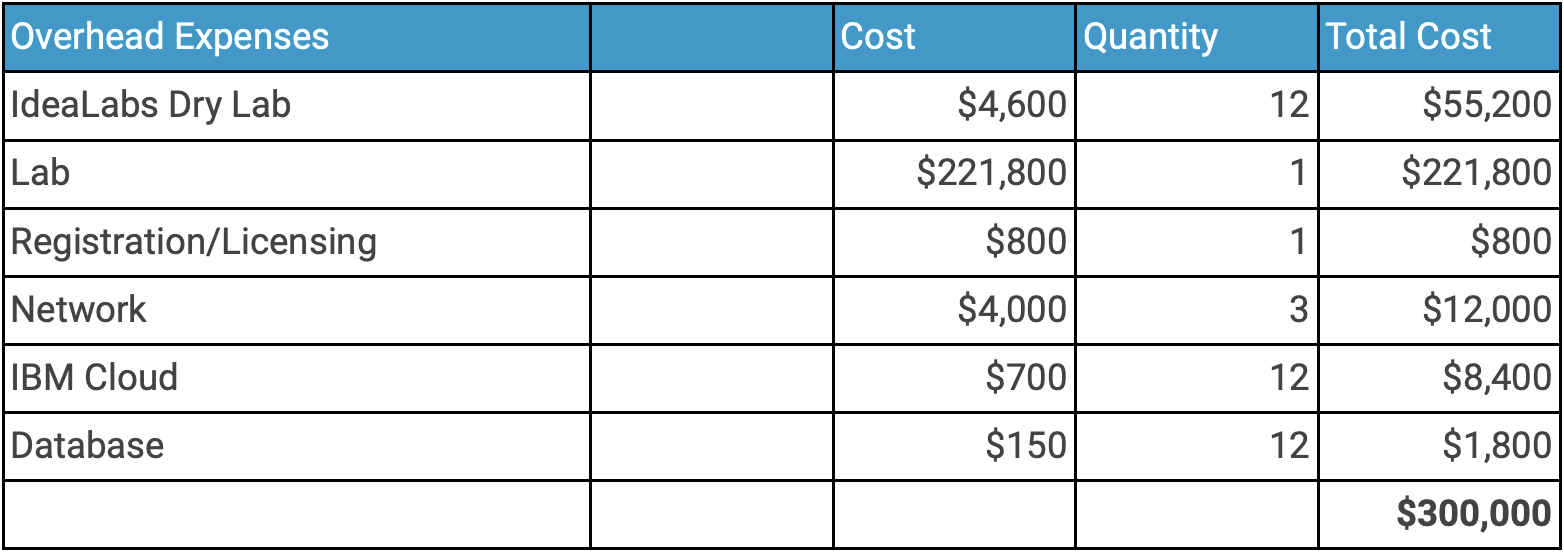
The goal of the Artificial Intelligence Institute of UofSC is to develop AI education and workforce, carry out world-class research in AI, and for social development with projects in good social health and good faith (AIISC, 2021). Perfect Run checks all these boxes, and would produce invaluable primary data. As project manager, I aim for the AIISC to invest $350,000 into this project, to cover staffing and some of the equipment needs. All proposals for AIISC involvement will be done via Dr. Amit Sheth, the Director of the AIISC. Seeing as the UofSC Innovation center has machine learning labs, through vendor negotiations with potentially working out of IdeaLabs dry lab as a last resort, the University could waive the overhead fee reserved for a lab. This would drastically drop the price down to $1,278,200, and with the AIISC’s investment, drop the total amount of bootstrapping and funding to $928,000. Perfect Run founding members will be involved in the raising capital part of the project months before launch. The additional funding will be raised through applying for Magellan Grants, AI/ML research grant opportunities and personal vested salaries.
References
WP Company. (2019, December 21). Federal study confirms racial bias of many facial-recognition systems, casts doubt on their expanding use. The Washington Post. https://www.washingtonpost.com/technology/2019/12/19/federal-study-confirms-racial-bias-many-facial-recognition-systems-casts-doubt-their-expanding-use/
Akselrod, O. (2023, July 3). How artificial intelligence can deepen racial and economic inequities: ACLU. American Civil Liberties Union. https://www.aclu.org/news/privacy-technology/how-artificial-intelligence-can-deepen-racial-and-economic-inequities
AIISC. (n.d.). https://aiisc.ai/research.html